
I have to admit, this article will sound a bit like an advertisement. But given that Cisco has gotten enough attention on this blog already, it can only bring variation into the mix.
A short explanation of a series of different products offered by F5 Networks. Why? If you’re a returning reader to this blog and work in the network industry, chances are you’ll either have encountered one of these appliances already, or could use them (or another vendor’s equivalent of course).

LTM
The Local Traffic Manager’s main function is load balancing. This means it can divide incoming connections over multiple servers.
Why you would want this:
A typical web server will scale up to a few hundred or thousand connections, depending on the hardware and services it is running and presenting. But there may be more connections needed than one server can handle. Load balancing allows for scalability.
Some extra goodies that come with it:
- Load balancing method: of course you can choose how to divide the connections. Simply round-robin, weighted in favor of a better server that can handle more, always to the server with the least connections,…
- SSL Offloading: the LTM can provide the encryption for HTTPS websites and forward the connections in plain HTTP to the web servers, so they don’t have to consume CPU time for encryption.
- OneConnect: instead of simply forwarding each connection to the servers in the load balancing pool, the LTM can set up a TCP connection with each server and reuse it for every incoming connection, e.g. a new HTTP GET for each external connection over the same inbound connection. Just like SSL Offloading, it consumes fewer resources on the servers. (Not every website handles this well.)
- Port translation: not really NAT but you can configure the LTM for listening on port 80 HTTP or 443 HTTPS while the servers have their webpage running on different ports.
- Health checks: if one of the servers in the pool fails, the LTM can detect this and stop sending connections to the server. The service or website will stay up, it will just be able to accept fewer resources. You can even upgrade servers one by one without downtime for the website (but make sure to plan this properly).
- IPv6 to IPv4 translation: your web servers and entire network does not have to be IPv6 capable. Just the network up to the LTM has to be.

ASM
The Application Security Manager can be placed in front of servers (one server per external IP address) and functions as an IPS.
Why you would want this:
If you have a server reachable from the internet, it is vulnerable to attack. Simple as that. Even internal services can be attacked.
Some extra goodies that come with it:
- SSL Offloading: the ASM can provide the encryption for HTTPS websites just like the LTM. The benefit here is that you can check for attack vectors inside the encrypted session.
- Automated requests recognition: scanning tools can be recognized and prevented access to the website or service.
- Geolocation blocks: it’s possible to block out entire countries with automatic lists of IP ranges. This way you can offer the service only where you want it, or stop certain untrusted regions from connecting.
GTM
The Global Traffic Manager is a DNS forwarding service that can handle many requests at the same time with some custom features.
Why you would want this:
This one isn’t useful if the service you’re offering isn’t spread out over multiple data centers in geographically different regions. If it is, it will help redirect traffic to the nearest data center and provide some DDoS resistance too.
Some extra goodies that come with it:
- DNSSec: secured DNS support which prevents spoofing.
- Location-based DNS: by matching the DNS request with a list of geographical IP allocations, the DNS reply will contain an A record (or AAAA record) that points to the nearest data center.
- Caching: the GTM also caches DNS requests to respond faster.
- DDoS proof: automated DNS floods are detected and prevented.

APM
The Access Policy Manager is a device that provides SSLVPN services.
Why you would want this:
The APM will connect remote devices with encryption to the corporate network with a lot of security options.
Some extra goodies that come with it:
- SSLVPN: no technical knowledge required for the remote user and works over SSL (TCP 443) so there’s a low chance of firewalls blocking it.
- SSO: Single Sign On support. Log on to the VPN and credentials for other services (e.g. Remote Desktop) are automatically supplied.
- AAA: lots of different authentication options, local, Radius, third-party,…
- Application publishing: instead of opening a tunnel, the APM can publish applications after the login page (e.g. Remote Desktop, Citrix) that open directly.
So what benefit would you have from knowing this? More than you think: many times when a network or service is designed, no attention is given to these components. Yet they can help scale out a service without resorting to complex solutions.






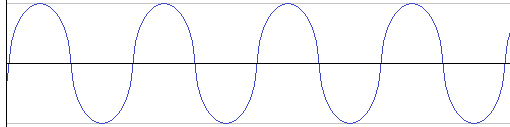
 So the above would be read as ‘0100’. I’m making an exaggeration here in the picture, displaying the ‘1’ as double the frequency as a ‘0’. In reality, it would be just slightly higher.
So the above would be read as ‘0100’. I’m making an exaggeration here in the picture, displaying the ‘1’ as double the frequency as a ‘0’. In reality, it would be just slightly higher.








