I’ve already made an introduction to the ASA, but when working with them on a regular basis, it’s nice to know some features that come with the product to explain how it reacts and help troubleshooting. So for the interested reader with little ASA experience, below a few features that have proven handy to me.
Full NAT & socket state
Most consumer-grade routers with NAT keep a NAT state table that keeps state only with the source socket . A socket is an IP address and port paired together. For example, the following setup:

When connecting to the web server, remote socket 198.51.100.5:80, a local socket, for example 192.168.1.2:37004 is created. The router will then do a NAT translation to its outside IP address (a NAT/PAT with overloading or hide NAT) to socket 203.0.113.10:37004. This means that if return traffic arrives for destination 203.0.113.10 port 37004, it will be translated to 192.168.1.2 port 37004. However, without stateful firewalling, any packet will be translated back in again on port 37004, regardless of source. This is how some software like torrent programs do NAT hole punching. Also, no matter how big the pool of private IP addresses, the public IP address translations have a maximum of about 64,000 ports available (okay, 65,535 technically but there are probably some reserved and a source port below 1,024 is generally not recommended).
The ASA handles this differently: in combination with the stateful firewall a full state is made for each connection, both source and destination socket. This means the above translation is still done but no return traffic from another source is allowed. On top of that, if another inside host makes a connection towards a different web server, the ASA can reuse that port 37004 for a translation. Return traffic from that different web server will be translated to the other inside host because the ASA keeps a full state. Result: no 64,000 ports per public IP address the device has, but 64,000 per remote public IP address! This allows for even more oversubscription of a single public IP address, assuming not everyone is going to browse the exact same website.

Sequence randomization
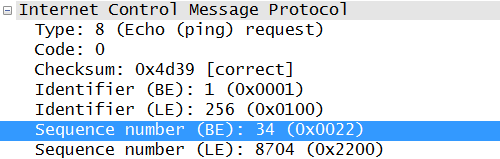
A bit further into layer 4: TCP uses sequence numbers to keep track of the right order in a packet flow. The initial sequence number is supposed to be random, but this is not often the case in practice. In fact, one quick Wireshark from a connection to Google gives me this:

The problem is that guessing sequence numbers allows an attacker to intercept a TCP connection or guess an operating system based on the sequence number pattern. That’s where the second nice-to-know ASA feature comes into play: sequence randomization. By adding a random number to each sequence number (the same random number for each packet per flow) it becomes impossible to guess the initial sequence number of the next connection, as well as difficult to do any OS fingerprinting based on it.
Inspect policy-maps
For someone not familiar with the ASA, this is often a point of trouble. By default the ASA has no awareness above layer 4. This means any information not in the UDP or TCP header isn’t checked. Examples are HTTP headers, the FTP port used for transfer (which is in the payload) and ICMP Sequence numbers.
ASA requires configuration of policy-maps for this. This is why by default ping requests through the ASA don’t work: it cannot create a state for it. And for HTTP inspect, it checks for proper HTTP headers as well as the presence of a user-agent header. This means non-HTTP traffic cannot be sent through port 80, and incoming telnets on port 80 towards web servers aren’t accepted either, preventing some scans.
Capturing
Finally, one of the most useful functions. While many other platforms with a Unix-based OS allow some form of tcpdump, Cisco does not support it. However, you can do some form of capturing on an ASA, even with proper filtering.
First configure the ACL that will be used as a filter, otherwise you’ll capture all traffic for that interface.
ASA#configure terminal
ASA(config)#access-list ExampleCapture extended permit ip host 172.16.16.16 any
ASA(config)#exit
Next, find the correct interface name: the ‘nameif’ because the usual interface name will not do.
ASA#show run int vlan16
!
interface Vlan16
nameif Internal
security-level 50
ip address 172.16.16.1 255.255.255.0
Now you can start and show the capture.
ASA#capture TestCap interface Internal access-list ExampleCapture
ASA#show capture TestCap
76 packets captured1: 16:45:13.991556 802.1Q vlan#16 P0 172.16.16.249.44044 > 203.0.113.10.22: S 3599242286:3599242286(0) win 8192 <mss 1460,nop,wscale 8,nop,nop,sackOK>
2: 16:45:14.035474 802.1Q vlan#16 P0 172.16.16.249.44044 > 203.0.113.10.22: . ack 1303526390 win 17520
3: 16:45:14.037824 802.1Q vlan#16 P0 172.16.16.249.44044 > 203.0.113.10.22: P 3599242287:3599242338(51) ack 1303526390 win 17520
4: 16:45:14.067196 802.1Q vlan#16 P0 172.16.16.249.44044 > 203.0.113.10.22: . ack 1303526754 win 17156
5: 16:45:14.072887 802.1Q vlan#16 P0 172.16.16.249.44044 > 203.0.113.10.22: P 3599242338:3599242898(560) ack 1303526754 win 17156
6: …
Note that traffic is seen in only one direction here. To see return traffic, add the reverse flow to the capture ACL as well. Unfortunately, the capture must stay running while watching the output here. The capture can be stopped as following:
ASA#no capture TestCap
This will erase the capture also, so the show command will no longer work.
Additionally, you can do a real-time by adding the parameter ‘real-time’, but it’s a bit more tricky. This is not recommended for traffic-intensive flows, but ideal to see if a SYN is actually arriving or not.
ASA#capture TestCap interface External access-list ExampleCapture real-time
Warning: using this option with a slow console connection may
result in an excessive amount of non-displayed packets
due to performance limitations.Use ctrl-c to terminate real-time capture
1: 16:45:51.755454 802.1Q vlan#16 P0 172.16.16.16.43969 > 203.0.113.10.22: . ack 2670019600 win 16220
2: 16:45:51.768698 802.1Q vlan#16 P0 172.16.16.16.43969 > 203.0.113.10.22: . ack 2670019768 win 17520
3: 16:45:51.768774 802.1Q vlan#16 P0 172.16.16.16.43969 > 203.0.113.10.22: . ack 2670019968 win 17320
4: 16:45:51.777501 802.1Q vlan#16 P0 172.16.16.16.43969 > 203.0.113.10.22: . ack 2670020104 win 17184
5: …
Just don’t forget to remove the ACL after you’re done.