If you ever managed a Campus LAN, you’ll know what happens with a lot of end users that have access to ethernet cables on desks. The occasional rogue hub, a loop now and then, and if they have access to some more advanced tools, some BPDU’s and a rogue DHCP server. Most of these events are not intended to be malicious (even the BPDU’s and rogue DHCP), but they happen because end users are not aware of the impact of some devices on the network.
But, given a malicious intend, what are the possibilities of attacking a switched Cisco network from a directly attached interface? Operating system for all the upcoming attacks: BackTrack Linux, which has many interesting tools installed.
MAC Flood
The classic attack first: flooding the switch’s CAM table with random source MAC addresses.
Tool: macof
Countermeasure: port-security
First attacking without port security: as expected, CAM table fills, CPU increases and everything is flooded. Congestion everywhere.

Finding this attack without port-security is feasible by checking CPU processes: HLFM address learning doesn’t normally consume that much CPU. Turning of MAC address learning does the same but without CPU impact.
So does turning port-security on solve the problem? It depends. Turning it on and setting it to only block new mac addresses but not shutting down the port actually makes things worse for the CPU:

The best solution: port-security with shutdown of the port in case of too many MAC addresses. No flooding, no CPU hogging.
CDP Flood
A Cisco-only attack. Flooding CDP frames with fake neighbors, causing not only CPU spikes, but also clogging the memory with all the neighbor entries. ‘show cdp neighbor’ becomes like showing the route table on a BGP router: endless.
Tool: Yersinia
Countermeasure: disabling CDP on the port or globally.
The attack with CDP turned on (the default) is very effective:

Finding the attack is easy, as both CPU and memory will clearly show the CDP process is using up resources. However, without CDP on the port, the attack does nothing. So the best solution: always turn CDP off towards a user-facing port. Even behind an IP Phone, although some functionality will be lost.
Root BPDU inject
A funny one. Inject a BPDU claiming to be root to cause spanning-tree recalculations and creating suboptimal paths in the network.
Tool: Yersinia
Countermeasure: Root Guard.

Notice the root ID, which has a nearly identical MAC address to make it difficult to spot the difference, and the aging time of two days, making this an attack that will last while the attacker is no longer connected. Root Guard on the port counters this attack easily though.
BPDU Flood
This attack doesn’t try to change the spanning-tree topology, but rather overload the STP process. Consequence is high CPU and eventually spanning tree inconsistencies.
Tool: Yersinia
Countermeasure: BPDU Guard

Spanning-tree should not use that much CPU on a switch. HLFM address learning will increase too due to the random source MAC addresses, and depending on the switch, Hulc LED Process will increase too. This is the process that governs the LED status of all switchports: the more ports the switch, the more this process will consume CPU if flooding attacks are happening.
BPDU Guard stops this effectively by shutting down the port. BPDU Filter not so much: it still needs to look at the BPDU to drop it and not forward it in hardware. BPDU Filter is generally not recommended anyway.
DHCP Discover Flood
Not really a layer 2 attack, but still impacting for the local subnet. Sending a flood of DHCP Discover messages, quickly overloading the DHCP Server(s) for the subnet.
Tool: Yersinia
Countermeasure: DHCP Snooping and DHCP Snooping Rate Limit
If DHCP Snooping isn’t enabled on the switch, it behaves like a MAC Flood attack and can be countered accordingly. Simply enabling DHCP Snooping, which is against rogue servers and not against flooding, makes things worse.
 Not only does it make the CPU spike, but it’s one of the few attacks that makes the switch unresponsive in the data plane, meaning not only management is lost, but the switch stops forwarding most frames, with packet loss on all ports. Simple snooping does prevent execution from a virtual machine:
Not only does it make the CPU spike, but it’s one of the few attacks that makes the switch unresponsive in the data plane, meaning not only management is lost, but the switch stops forwarding most frames, with packet loss on all ports. Simple snooping does prevent execution from a virtual machine:

But to really protect against this attack, DHCP Snooping rate-limiting helps:

OSPF Flood
Sending a flood of OSPF Hello packets over a switch.
Tool: a virtual machine running ospfd (Vyatta, OpenBSD), and a hub between switch and computer with cable loop to cause the flood.
Countermeasure: ACL
For this one I didn’t use any specific tool. I just made my computer send out an OSPF Hello, and made sure the hub between computer and switch was wired so it would flood the frame. Result: spectacular. The switch CPU rises to 100% and management connections, including console, are dropped. Reason is that the OSPF process has higher priority. But now the shocking part: this was done on a layer 3 Cisco switch without OSPF configured, and without an IP address in the attacker VLAN.
Explanation: Cisco switches use something called pak_priority. It means that certain packets on ingress are labeled by the interface driver as priority and to be checked by CPU (Source). This is done to make sure network control packets get to the CPU in case of congestion. It’s the case for RIP, OSPF and EIGRP, but not for BGP packets.
I retried it with EIGRP (although this required a second Cisco device to generate the EIGRP hello) and the result is the same: no EIGRP configuration on the switch, still impact. The data plane does not have any impact: forwarding stays as usual mostly.
Solution? Strange enough, an ACL on each port blocking EIGRP (IP Protocol 88) and OSPF (IP Protocol 89) and allowing everything else seems to work. The ACL is checked in hardware as long as the ‘log’ parameter isn’t present. So for better security, it seems you’re stuck with an ACL on each switchport of a layer 3 switch.
Conclusion
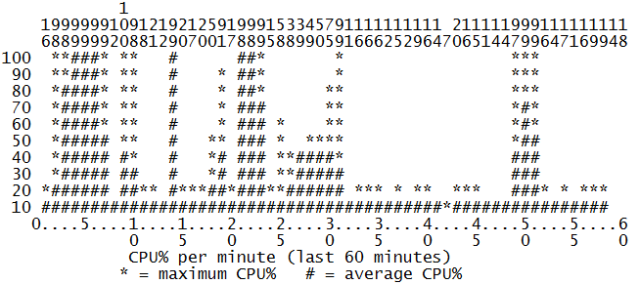
I’m sure most of the readers now conclude that there’s still a security leak somewhere in their network. Just for reference, I’ll include the CPU graph of an hour of testing all these attacks.